User Guide 2: Understanding the data
Introduction
In Guide 1, we ran our first importance sampling simulation using PyFPT. It was applied to quadratic inflation, with the result that the numerically reconstructed probability density deviated from the analytical expectation in the tail of the distribution. This comparison was done using the analytics module of PyFPT.
However, we treated the numerical results of the PyFPT package as a black box and used the default values. In this Notebook, we will look at better understanding the simulated data, and introduce some of the optional arguments for fpt.numerics.is_simulation. The aim is to start to demystify fpt.numerics.is_simulation. To further this aim, if a new optional argument is introduce used, it will be specified in the section heading as well.
Once this is done, we will use this knowledge to combine data sets to numerically reconstruct the probability density from the peak of the distribution all the way into the very rare events in the far tail.
Context - Importance Sampling
Importance sampling is achieved by a introducing a bias to the slow-roll Langevin equation to over sample the large \(\mathcal{N}\)
where \(H\) is the Hubble parameter, \(\xi\) is a unit variance Gaussian white noise and \(\mathcal{B}\) is the bias introduced. You imagine the bias as a wind pushing against the drift term (the first term above), meaning it takes longer for the field \(\phi\) to evolve from \(\phi_i\) to \(\phi_{\rm end}\). Therefore, the probability of a run having a larg \(\mathcal{N}\), and thus a large curvature perturbation by the stochastic \(\delta N\)-formalism, is greater.
There is a choice in the functional form of the bias \(\mathcal{B}(\phi)\) used. A simple choice is to have it proportional to diffusion,
where the parameter \(\mathcal{A}\), known as the bias amplitude, can be used to tune how strong the bias is. This is the default choice for fpt.numerics.is_simulation, but you can provide any function as long as it takes (x, t) as its argument.
Of course, the above Langevin equation results in a slightly different stochastic path than if no bias was present. The relative probability that this stochastic path is achieved without \(\mathcal{B}\) being present then gives the statistical weight of this realisation of the Langevin equation. For the biased Langevin equation above and discrete steps \(\Delta N\) steps, which resulted in the path \(\mathbf{Y} = (\phi_1, \phi_2,...\phi_{M})\) of \(M\) steps starting at \(\phi_i\), the weight is
Knowing the value of \(w\) for each path then allows \(P(\mathcal{N})\) to estimated.
Plotting the Raw Data (save_data)
Previously, we only plotted the already processed \(P(\mathcal{N})\) data. As importance sampling alone results in two data sets, one for the FPTs \(\mathcal{N}\) and another for associated weights \(w\) of this sampled path, one needs to use data processing.
To do this, lets first understand the relation \(\mathcal{N}\) and \(w\). This is most easily done using a 2D histogram and requires that the raw \(\mathcal{N}\) and \(w\) data is saved when fpt.numerics.is_simulation is run. We can do this using the optional argument save_data. As before, we will also import the other packages we need, define the potential and the drift/diffusion first.
[1]:
import pyfpt as fpt
import numpy as np
import matplotlib.pyplot as plt
import mpl_style
plt.style.use(mpl_style.paper_style)
# Will also need pandas to read saved raw the data
import pandas as pd
# Also need colours for a 2D histogram
from matplotlib.colors import LogNorm
[2]:
phi_in = 42**0.5 # From N=0.25*(phi_in**2-phi_end**2) = 10
phi_end = 2**0.5 # Where slow-roll violation occurs
# For the above phi_in, this mass is the interim case.
m = 0.1
# Any slow-roll potential and its derivatives could be defined here
def V(phi):
V = 0.5*(m*phi)**2
return V
def V_dif(phi):
V_dif = (m**2)*phi
return V_dif
def V_ddif(phi):
V_ddif = (m**2)
return V_ddif
# Again, we need to define the drift and diffusion based on this potential
def drift_func(phi, N):
return -2/phi
def diffusion_func(phi, N):
pi = 3.141592653589793
sqirt_6 = 2.449489742783178
return (m*phi)/(2*pi*sqirt_6)
[3]:
# The number of simulation runs
num_runs = 2*10**5
bias_amp = 1.
# Estimate a reasonable time step to use
std = fpt.analytics.variance_efolds(V, V_dif, V_ddif, phi_in, phi_end)**0.5
dN = std/(2*50)
Now let’s run the same simulation as before, but save the raw \(\mathcal{N}\) and \(w\) data this time.
[4]:
# Returns the normalised histogram bin centres, heights and
# errors as a lists. Optional argument given to save raw data.
bin_centres, heights, errors =\
fpt.numerics.is_simulation(drift_func, diffusion_func, phi_in, phi_end, num_runs,
bias_amp, dN, save_data=True)
# Easier to use numpy arrays rather than lists
bin_centres = np.array(bin_centres)
heights = np.array(heights)
errors = np.array(errors)
Number of cores used: 4
The simulations took: 439.0368523509969 seconds
Saved data to file IS_data_x_in_6.48_iterations_200000_bias_1.0.csv
The raw data was saved to a comma separated value (.csv) file using pandas called “IS_data_x_in_6.48_iterations_200000_bias_1.0.csv” in the same directory as this Notebook.
By saving this data, we can also reanalyse it with different methods using the function ``fpt.numerics.data_points.pdf``.
Now we can again use pandas to read the data from the file
[5]:
raw_data = pd.read_csv('IS_data_x_in_6.48_iterations_200000_bias_1.0.csv', index_col=0)
# Easier to work with NumPy arrays
N_values = np.array(raw_data['FPTs'])
w_values = np.array(raw_data['ws'])
Now do let’s do a 2D histogram as a colour map.
[6]:
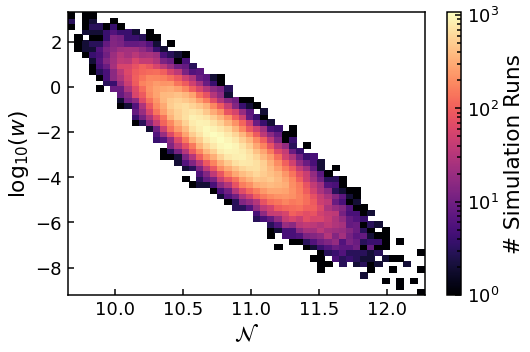
plt.hist2d(N_values, np.log10(w_values), (50, 50), norm=LogNorm())
cbar = plt.colorbar()
cbar.set_label(r'# Simulation Runs')
plt.xlabel(r'$\mathcal{N}$')
plt.ylabel(r'${\rm log}_{10}(w)$')
plt.show()
plt.clf()
<Figure size 576x374.4 with 0 Axes>
Clearly, there is not a one-to-one relation between the FPT in e-folds of an importance sampling simulation run \(\mathcal{N}\) and its weight \(w\). Instead, there is a correlation between \({\rm log}_{10}(w)\) and \(\mathcal{N}\), with the majority of the data at the centre. This means that within any particular \(\mathcal{N}\) bin, \(w\) can vary by orders of magnitude. As we have a finite number of data points within each bin and naïvly the value of \(P(\mathcal{N})\) is just the normalsied sum of the \(w\)s within the bin, how can we accurately estimate \(P(\mathcal{N})\)? As surely the sum will be dominated just by the few largest \(w\) values?
The answer is to use the fact that \(w\) follows a lognormal distribution, meaning \(\ln (w)\) follows normal (Gaussian) distribution. See Jackson *et al* 2022 for explanation of why this is. Therefore, if we can calculate the mean and variance of \(\ln (w)\), denoted as \(\mu\) and \(\sigma\) respectively, then the mean of \(w\) is given by
The sum of \(w\) with a particular bin is then (by the definition of the mean)
where \(n\) is the number of runs within the bin of interest. This method has the advantage that it utilises all of the data equally and is therefore not dominated by the few largest \(w\) values.
The lognormal assumption is the default estimator used in fpt.numerics.is_simulation, i.e. estimator='lognormal' is the default argument. One can also use estimator='naive' for the naïve estimator.
Combining Data Sets
An important point to observe in the 2D histogram above, is that the mean of the sampled \(\mathcal{N}\) is centred around \(\sim 10.8\) but the mean of the target distribution, due to the \(\phi_i\) value used, is 10. Therefore, the sample distribution is simply shifted compared to the target distribution. It is the value of the weights which reconstructs the target distribution and is most accurately reconstructed about the mean of the sample distribution.
Put simply, for \(m=0.1\) used here, as the bias amplitude \(\mathcal{A}\) is increased, PyFPT probes further and further into the tail of \(P(\mathcal{N})\). This leads to the question, could we run a series of simulations sets of increasing \(\mathcal{A}\) and combine. The answer is: yes we can!
Storing Results and Loops (bins)
To plot the results from multiple importance samples, we need to run multiple importance samples and store the data. This can be done using a for loop and empty NumPy arrays.
But first, we need to define what our range of bias amplitudes will be. Note I’ve include a value of zero, to allow comparison with a direct simulation with no importance sampling.
[7]:
bias_amp_range = np.array([0., 1., 2., 3.])
Now let’s set up empty arrays to store the results. To do this we need to know the length of the returned data lists, which corresponds to the number of bins used in the histogram of \(\mathcal{N}\). There is optional argument for fpt.numerics.is_simulation called bins. If bins is an integer, this is simply the number of evenly spaced bins used. If bins is a list or numpy array, it defines the bin edges, including the left edge of the first bin and the right edge of the last bin.
The widths can vary. The default is 50 evenly spaced bins, i.e. bins=50 in fpt.numerics.is_simulation, which was found in practice to be a good descriptor of the data but we will still pass this as an argument for clarity.
As we know the size of the returned lists and the number of them, storage arrays can be defined.
[8]:
num_bins = 50 # Number of evenly spaced bins used in the histogram
# Empty arrays to store values
bin_centres_storage = np.zeros((num_bins, len(bias_amp_range)))
heights_storage = np.zeros((num_bins, len(bias_amp_range)))
# Errors do not assume symmetry, so need a 3D array as each `error' has two values
errors_storage = np.zeros((len(bias_amp_range), 2, num_bins))
A for loop can be used to run a set of runs for each bias value in bias_amp_range.
[9]:
for i, bias_amp in enumerate(bias_amp_range):
print('Now simulating for bias amplitude '+str(bias_amp))
bin_centres, heights, errors =\
fpt.numerics.is_simulation(drift_func, diffusion_func, phi_in, phi_end,
num_runs, bias_amp, dN, save_data=True,
estimator='lognormal', bins=num_bins)
# Storing the results in NumPy arrays
bin_centres_storage[:len(bin_centres),i] = bin_centres
heights_storage[:len(heights),i] = heights
# Remeber this is a 3D array
errors_storage[i,:,:len(heights)] = errors
Now simulating for bias amplitude 0.0
As direct simulation, defaulting to naive estimator
Number of cores used: 4
The simulations took: 441.9654535570007 seconds
/home/jjackson/anaconda3/lib/python3.8/site-packages/numpy/lib/function_base.py:2559: RuntimeWarning: invalid value encountered in true_divide
c /= stddev[:, None]
/home/jjackson/anaconda3/lib/python3.8/site-packages/numpy/lib/function_base.py:2560: RuntimeWarning: invalid value encountered in true_divide
c /= stddev[None, :]
Saved data to file IS_data_x_in_6.48_iterations_200000_bias_0.0.csv
Now simulating for bias amplitude 1.0
Number of cores used: 4
The simulations took: 483.4304898370028 seconds
Saved data to file IS_data_x_in_6.48_iterations_200000_bias_1.0.csv
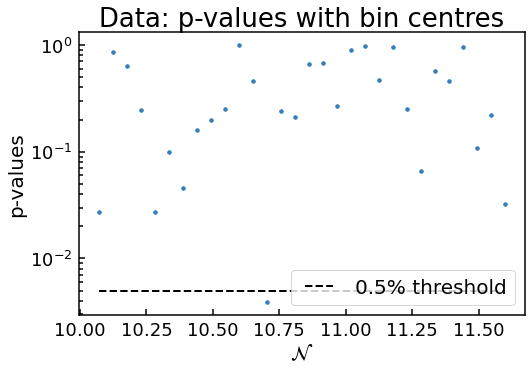
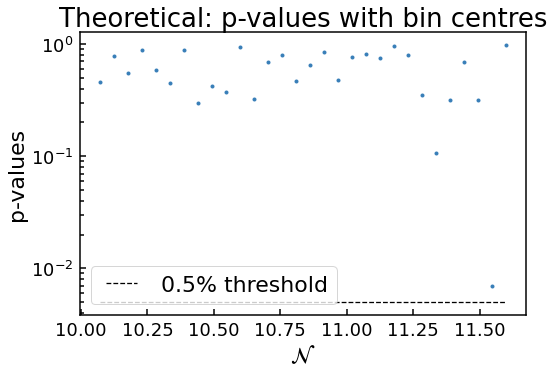
Possibly not lognormal distribution, see p-value plots
Now simulating for bias amplitude 2.0
Number of cores used: 4
The simulations took: 542.4852338399942 seconds
Saved data to file IS_data_x_in_6.48_iterations_200000_bias_2.0.csv
Now simulating for bias amplitude 3.0
Number of cores used: 4
The simulations took: 518.6787533780007 seconds
Saved data to file IS_data_x_in_6.48_iterations_200000_bias_3.0.csv
Context - p-values Plots
Notice how two plots were outputted for the simulation with bias_amp of 1? This is because one of the \(p\)-values (which is the probability that the data is drawn from an underlying lognormal distribution) for the \(w\) values in the \(\mathcal{N}\) bin near 10.75 is below the 0.5% threshold. This tells the code to check with the user to see if the approximation that the distribution of \(w\) within each bin is given by a lognormal distribution. Determining if this is the
case can be difficult, as randomly we expect some of the \(p\)-values to be below the threshold. That’s why the theoretical \(p\)-values, where each bin has \(w\) values randomly drawn from a true lognomral distribution, are given for comparison.
For this case, as only one \(p\)-value is below the threshold and the two plots look very similar, it is safe to assume the lognormal approximation is valid. On the other hand, if several \(p\)-values were smaller than \(10^{-15}\) say, but it’s highly probable the approximation is invalid. On the other hand, there could be a borderline case with 5 data points only just below the threshold. This of course requires some judgement of the user. But generally, as the number of runs is increased, the \(p\)-values get even smaller if it is NOT a lognormal distribution. So one can just run the simulation again with more runs for these borderline cases to determine if lognormal approach can be used.
Bin Truncation (min_bin_size)
Note my use above of :len(heights) when storing the results. This is because by default, if any bin with less than 400 runs is truncated and the length of heights may be less than the number of bins provided. The truncation is a conservative measure, to make sure only data points where the error estimation is accurate is plotted. But if want to much less conservative and only require, say, 100 runs? This can be done with the optional argument min_bin_size=100 in
fpt.numerics.is_simulation. The default is 400, as a conservative value.
Plotting the Combined Data
As we have the results stored, again we can use a for loop to over plot all of this data, as well as the Gausiian and Edgeworth approximations.
[10]:
for i, bias_amp in enumerate(bias_amp_range):
# Slicing the ith data
bin_centres_temp = bin_centres_storage[:,i]
heights_temp = heights_storage[:,i]
# Remeber there are lower and upper errors, so it's a 3D array.
errors_temp = errors_storage[i,:,:]
# Remove the zero values array padding
errors_temp = errors_temp[:,heights_temp>0]
bin_centres_temp = bin_centres_temp[heights_temp>0]
heights_temp = heights_temp[heights_temp>0]
# Plotting the direct sample using red
if round(bias_amp,4) == 0.:
plt.errorbar(bin_centres_temp, heights_temp, yerr=errors_temp,
fmt=".", ms=7, label='{0}'.format(r'Direct'),
color = '#e41a1c')
# The rest of the importance samples use standard colours
else:
plt.errorbar(bin_centres_temp, heights_temp, yerr=errors_temp,
fmt=".", ms=7, label='{0}'.format(r'$\mathcal{A}$='+str(bias_amp)))
# Analytical functions
gaussian_pdf = fpt.analytics.gaussian_pdf(V, V_dif, V_ddif, phi_in, phi_end)
edgeworth_pdf = fpt.analytics.edgeworth_pdf(V, V_dif, V_ddif, phi_in, phi_end)
# Need to convert2D to 1D for plotting analytical curves
bin_centres_combined = bin_centres_storage.flatten()
# Remove the empty values
bin_centres_combined = np.sort(bin_centres_combined[bin_centres_combined>0])
# Plotting analytical expectations
plt.plot(bin_centres_combined, gaussian_pdf(bin_centres_combined),
label='{0}'.format('Gaussian'), color='k')
plt.plot(bin_centres_combined, edgeworth_pdf(bin_centres_combined),
label='{0}'.format('Edgeworth'), color='k', linestyle='dashed')
# Smallest y value plotted corresponding to data
plt.ylim(bottom = np.min(heights_storage[heights_storage>0]))
# Need to use log scale to see data in the far tail
plt.yscale('log')
plt.xlabel(r'$\mathcal{N}$')
plt.ylabel(r'$P(\mathcal{N})$')
plt.legend()
[10]:
<matplotlib.legend.Legend at 0x7f88a514ba90>
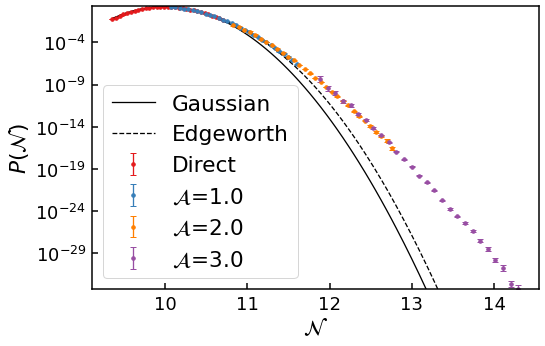
In the above graph, with a total simulation time of a short lunch break (\(\sim 30\) minutes), we have been able to numerically reconstruct the probability density \(P(\mathcal{N})\) from the peak of the distribution all the way down to \(10^{-31}\)! And the results overlap too, showing they are self-consistent!
Clearly, the numerical data agrees with the Gaussian and Edgeworth approximations before deviating strongly in the tail. In the far tail, this deviation is very large: the numerical data point at \(\mathcal{N}\sim 13\) has a probability density \(P(\mathcal{N})\) \(10^8\) times larger than the Edgeworth prediction. Discovering this boost to \(P(\mathcal{N})\) in the tail is only possible using the method of importance sampling.
Other Potentials and Masses
We can do the exact same procedure of increasing the bias amplitude \(\mathcal{A}\) to probe further and further into the tail for other potentials, as long as diffusion effects are not dominating. Indeed, for smaller mass \(m\), where diffusion effects are very small and the Gaussian prediction should hold far into the tail, PyFPT was able to reproduce this effect.
However, for diffusion domination, the importance sampling technique becomes much less effective, as we will see in the next guide.
Summary
In this guide, we have briefly touched on the method of importance sampling and the raw data it produces, then the different data analysis techniques to reconstruct the probability density \(P(\mathcal{N})\). Along the way, we have introduced some of the optional arguments for fpt.numerics.is_simulation, allowing us to customize the data analysis. Finally, we used this knowledge to combine multiple importance samples together to reconstruct \(P(\mathcal{N})\) from the peak of the
distribution all the way down to \(10^{-31}\)!
In the next and final guide, we will look at the numerically more difficult diffusion domination case. This will let us introduce the final optional arguments for fpt.numerics.is_simulation and analytical tools, as well as discuss some of the limitations of PyFPT.
[ ]: